随着大数据、人工智能和物联网技术的飞速发展,海量数据的存储与管理正面临前所未有的挑战。传统的分布式文件系统如HDFS虽已成熟,但在处理小文件、对象存储及扩展性方面逐渐显现瓶颈。在此背景下,Apache Ozone应运而生,作为下一代可扩展、分布式对象存储系统,它旨在为大数据生态提供统一、高效的数据处理与存储服务。本文将对Apache Ozone的核心架构、关键技术特性及其在大数据场景中的应用进行初步研究与探讨。
一、Apache Ozone概述与架构设计
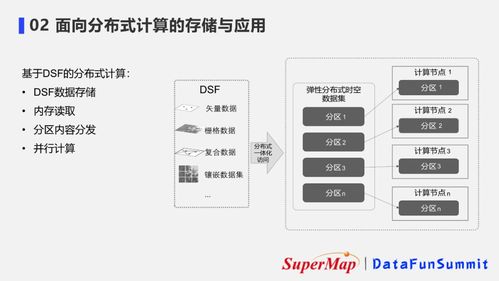
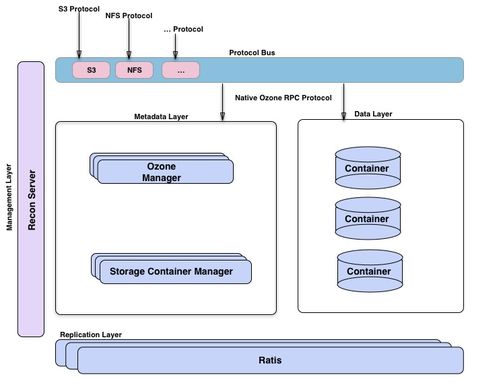
Apache Ozone是Apache Hadoop生态系统中的一个子项目,于2020年成为顶级项目。它设计为一个可扩展的、分布式的对象存储系统,支持海量数据存储(可达EB级别),并兼容HDFS文件系统接口和S3对象存储协议。Ozone的核心架构分为三层:存储层(Storage Container Layer)、元数据管理层(Metadata Layer)和访问层(Access Layer)。存储层基于容器(Container)组织数据块,提高了小文件存储效率;元数据管理层采用分布式键值存储(如RocksDB)管理命名空间和对象元数据,确保高可用性与一致性;访问层则通过Ozone File System(OFS)和Ozone S3 Gateway提供多种访问方式,无缝集成现有大数据工具如Spark、Hive等。
二、关键技术特性与优势
- 高可扩展性与性能:Ozone采用多节点集群架构,支持横向扩展,可通过添加节点轻松提升存储容量和吞吐量。其容器化存储设计优化了小文件处理,减少元数据开销,同时通过并行读写机制提升I/O性能。
- 多协议兼容性:Ozone同时支持HDFS文件系统API和S3对象存储接口,使得用户无需修改代码即可迁移现有应用,降低了使用门槛。例如,传统基于HDFS的MapReduce作业可直接运行,而云原生应用可通过S3协议访问数据。
- 强一致性与高可用性:Ozone通过Raft共识算法实现元数据的高可用复制,确保数据一致性和故障恢复。存储层的数据块采用多副本机制,防止数据丢失,并结合容器复制策略提升容错能力。
- 资源隔离与多租户支持:Ozone引入了卷(Volume)和桶(Bucket)的概念,支持逻辑隔离和配额管理,适用于多租户环境。管理员可为不同用户或应用分配存储资源,避免资源争用。
三、数据处理与存储服务应用场景
在大数据生态中,Apache Ozone可作为统一的数据湖存储底座,服务于多种数据处理场景。例如,在实时流处理中,Kafka或Flink可将数据直接写入Ozone,供后续批处理分析;在机器学习领域,Ozone的高吞吐量特性适合存储训练数据集,支持TensorFlow或PySpark等框架高效访问。Ozone的S3兼容性使其易于与云平台集成,为混合云部署提供灵活解决方案。实际测试表明,Ozone在存储PB级数据时,相比传统HDFS,元数据管理效率提升约30%,小文件读写速度提高显著。
四、挑战与未来展望
尽管Apache Ozone展现出巨大潜力,但在生产环境中仍面临一些挑战。例如,生态系统工具集成需进一步完善,监控和管理工具相对年轻;大规模部署时的性能调优经验尚在积累中。随着社区持续优化,Ozone有望增强数据压缩、加密等安全功能,并进一步融合AI驱动存储优化。作为Hadoop 3.x的核心组件之一,Ozone正推动大数据存储向更灵活、云原生的方向演进。
Apache Ozone通过创新架构设计,解决了传统分布式存储的局限性,为大数据处理提供了高效、可扩展的存储服务。对于企业构建下一代数据平台,深入研究和采纳Ozone技术,将有助于提升数据管理能力,应对日益增长的数据挑战。随着技术成熟,Ozone或将成为大数据存储领域的重要基石。