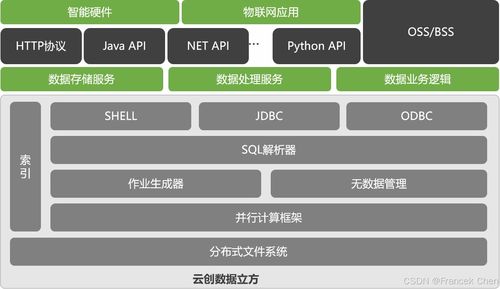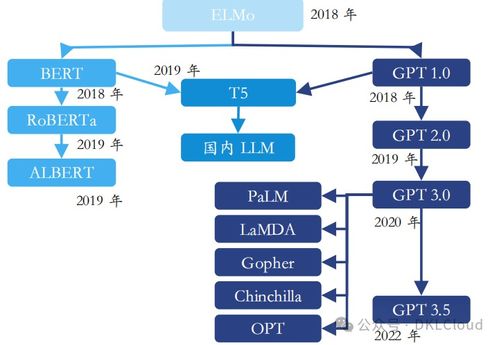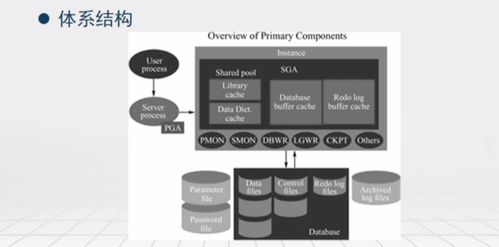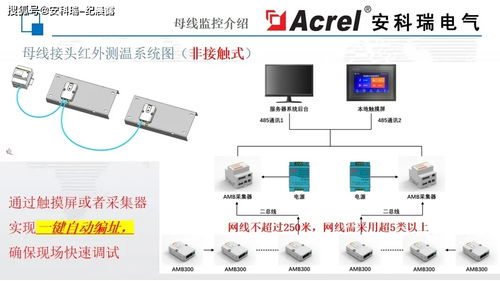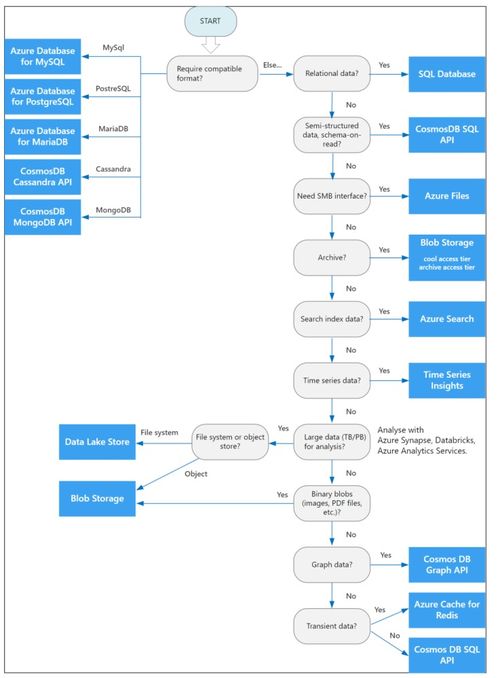
在构建云应用程序时,数据存储与处理服务的选择至关重要。Azure 提供了丰富的数据服务,覆盖结构化、非结构化、实时流处理与分析等多种场景。本指南将帮助您根据业务需求,选择最适合的 Azure 数据存储与处理服务。
一、核心数据存储服务
- Azure SQL Database
- 适用场景:关系型数据、需要强一致性、事务支持的应用(如 ERP、CRM)。
- 特点:全托管 SQL Server 引擎,支持自动备份、高可用与弹性扩展。
- Azure Cosmos DB
- 适用场景:全球分布式应用、低延迟读写、多模型数据(文档、键值、图等)。
- 特点:多区域复制、SLA 保证的吞吐量与延迟,支持 NoSQL 及 API 兼容(如 MongoDB、Cassandra)。
- Azure Blob Storage
- 适用场景:非结构化数据存储(如图片、视频、日志文件、备份)。
- 特点:低成本、高可扩展,提供热、冷、归档存储层级。
- Azure Data Lake Storage
- 适用场景:大数据分析、数据湖架构,存储海量结构化与非结构化数据。
- 特点:兼容 Hadoop 生态系统(如 Azure Databricks、HDInsight),支持细粒度权限控制。
- Azure Table Storage
- 适用场景:半结构化 NoSQL 数据,需要低成本、高吞吐存储(如设备元数据、用户配置)。
- 特点:键值存储模型,通过分区键实现高效查询。
二、数据处理与分析服务
- Azure Synapse Analytics
- 适用场景:企业级数据仓库、大规模并行处理(MPP)、集成分析与数据管道。
- 特点:统一的数据集成、数据仓库与大数据分析平台,支持 SQL 与 Spark 引擎。
- Azure Databricks
- 适用场景:协同式大数据分析、机器学习、实时流处理(基于 Apache Spark)。
- 特点:与 Azure 生态深度集成,提供自动化集群管理与交互式工作区。
- Azure HDInsight
- 适用场景:开源大数据框架托管服务(如 Hadoop、Spark、Kafka、HBase)。
- 特点:全托管集群,支持多种开源组件,适合迁移现有 Hadoop 工作负载。
- Azure Stream Analytics
- 适用场景:实时流数据处理(如 IoT 传感器数据、日志分析、实时仪表板)。
- 特点:无服务器流处理,使用类 SQL 语言进行事件处理,低延迟输出。
- Azure Data Factory
- 适用场景:数据集成与 ETL/ELT 管道,跨云或本地数据源的数据移动与转换。
- 特点:可视化设计器,支持超过 90 种数据连接器,调度与监控工作流。
三、选择策略与最佳实践
- 明确数据特性:分析数据规模、结构(结构化/半结构化/非结构化)、读写模式与一致性要求。
- 考虑性能需求:评估延迟、吞吐量、并发连接数及 SLA 要求。
- 规划扩展性与成本:根据增长预期选择弹性扩展方案,利用存储分层(如 Blob 的热/冷层)优化成本。
- 集成生态系统:优先选择能与现有工具链(如 Power BI、Azure Machine Learning)无缝集成的服务。
- 安全与合规:利用 Azure 加密、虚拟网络服务终结点、身份认证(如 Azure AD)保障数据安全。
四、典型场景示例
- 电商平台:用户数据与交易记录使用 Azure SQL Database;商品图片与日志存储于 Azure Blob Storage;实时推荐系统通过 Azure Cosmos DB 处理用户行为数据。
- 物联网监控:设备遥测数据通过 Azure Stream Analytics 实时处理;历史数据存储于 Azure Data Lake Storage 供 Azure Databricks 进行批量分析。
- 企业数据仓库:多源数据通过 Azure Data Factory 集成到 Azure Synapse Analytics,使用 Power BI 进行可视化。
通过综合评估业务需求与技术特性,您可以构建高效、可扩展且成本优化的 Azure 数据解决方案。下一章我们将深入探讨 Azure 中的网络与安全服务配置。